
Dr.부동산
[ 시계열 분석 ] ARIMA와 VAR 모델의 개념 및 응용 본문
시계열 분석 심층 보고서: ARIMA와 VAR 모델의 개념 및 응용
본 보고서는 시계열 예측 및 분석 분야에서 가장 널리 사용되는 두 가지 핵심 방법론인 자기회귀통합이동평균(ARIMA) 모델과 벡터 자기회귀(VAR) 모델의 근본적인 개념, 수학적 구조, 그리고 응용에 필요한 전처리 과정을 단계적으로 상세히 설명합니다.
I. 시계열 분석의 기초: 정상성(Stationarity)과 전처리 기법
통계적 시계열 모델링의 성공은 데이터가 정상성(Stationarity)이라는 핵심 가정을 충족하는지에 달려 있습니다. 비정상성 시계열을 분석 가능한 형태로 변환하는 과정은 ARIMA와 VAR 모델 구축의 첫걸음입니다.
1.1 시계열 데이터와 정상성(Stationarity)의 정의
시계열 데이터는 시간 인덱스를 가지며 연속적인 관측치 사이에 의존성(Dependence)이 존재하는 것이 특징입니다. 모든 통계적 시계열 모델의 잔차가 궁극적으로 만족해야 할 이상적인 형태는 백색잡음(White Noise) 과정이며, 이는 평균이 0이고 분산이 인 독립적인 오차항으로 구성됩니다.
정상성이란 시계열의 통계적 특성, 즉 평균, 분산, 그리고 자기공분산 구조가 해당 시계열이 관측된 시간에 무관하게 일정하게 유지됨을 의미합니다. 현실적인 모델링을 위해서는 약한 정상성(Weak Stationarity)을 충족해야 하는데, 이는 시계열의 기댓값()이 일정하고, 자기공분산()이 시간에 의존하지 않고 오직 시차(k)에만 의존해야 한다는 필수 조건입니다.
정상성을 나타내지 않는 비정상성 시계열은 추세(Trend)나 계절성(Seasonality)을 가지거나, 시간이 지남에 따라 분산이 변하는 이분산성(Heteroscedasticity)을 보입니다. 이러한 비정상성 시계열의 ACF(자기상관 함수) 그래프는 느리게 0으로 감소하는 특징을 보이며, 첫 번째 자기상관 값()이 종종 큰 양수 값을 가집니다.
1.2 정상화 기법: 차분(Differencing)의 원리와 적용
차분(Differencing)은 비정상성 시계열을 정상성을 나타내는 시계열로 변환하는 가장 일반적인 방법입니다. 차분은 연이은 관측값들의 차이를 계산하는 것으로, 시계열의 수준에서 나타나는 변화를 제거하여 시계열의 평균 변화를 일정하게 만드는 데 도움이 되며, 결과적으로 추세나 계절성을 제거하거나 감소시킵니다.
1차 차분 (First Difference)
1차 차분은 연속적인 관측값 사이의 변화(속도)를 모델링합니다. 수식은 다음과 같습니다:
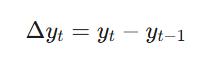
만약 원래 시계열이 확률보행(Random Walk) 모델()을 따른다면, 1차 차분된 시계열은 백색잡음이 됩니다. 차분값은 첫 번째 관측값에 대한 차분을 구할 수 없기 때문에, 원본 시계열보다 개의 값만 가지게 됩니다.
2차 차분 (Second Difference)
가끔 1차 차분으로도 정상성이 만족되지 않을 때, 한 번 더 차분을 구하는 작업이 필요할 수 있습니다. 2차 차분은 원본 데이터의 **"변화에서 나타나는 변화"**를 모델링하는 것과 같으며, 이는 물리적인 가속도(Acceleration)의 개념과 유사한 동태적인 변화율을 포착합니다.
2차 차분의 수식은 다음과 같습니다:

실제 상황에서는 2차 차분 이상이 필요한 경우는 매우 드뭅니다. 만약 ARIMA 모델에서 2차 차분()이 적용된다면, 모델의 계수는 원본 시계열의 수준이나 변화가 아닌, 이 가속도의 예측 오차를 모델링하는 것으로 해석적 복잡도가 높아집니다.
계절성 차분 (Seasonal Differencing)
계절성 차분은 계절성을 제거하기 위해 관측치와 같은 계절의 이전 관측값과의 차이를 계산합니다. 을 주기로 할 때 수식은 $y_t - y_{t-m}$이며, 예를 들어 월별 데이터에서 라면 올해 1월 값에서 작년 1월 값을 뺍니다. 계절성 패턴이 강하게 나타나면, 1차 차분보다 계절성 차분을 먼저 계산하는 것이 정상성을 달성하는 데 더 효과적일 수 있습니다.
1.3 정상성 진단: 단위근 검정 (Unit Root Tests)
정상성을 만족시키는지 확인하기 위해 그래프를 통한 직관적인 판단과 통계적 검정 방법이 병행되어야 합니다. 시간 그래프에서 평평하고 일정한 분산을 보이며, ACF 플롯이 비교적 빠르게 0으로 떨어지는지 확인하는 것이 기본입니다. 통계적 검정 방법으로는 ADF(Augmented Dickey-Fuller) 검정과 KPSS(Kwiatkowski-Phillips-Schmidt-Shin) 검정이 주로 사용됩니다.
- ADF 검정:
- 귀무가설(): 시계열에 단위근이 존재한다 (즉, 비정상성이다).
- 해석: p-값이 유의 수준(예: 0.05)보다 작아 귀무가설을 기각하면, 시계열이 정상성을 띤다고 판단합니다.
-
- KPSS 검정:
- 귀무가설(): 시계열에 정상성이 나타난다.
- 해석: p-값이 유의 수준보다 작아 귀무가설을 기각하면, 차분을 구하는 것이 필요하다는 것을 나타냅니다.
-
이 두 검정은 귀무가설이 서로 반대입니다. 분석가는 ADF 검정의 귀무가설을 기각하고 동시에 KPSS 검정의 귀무가설을 기각하지 않는 결과를 통해 시계열의 정상성 여부를 확신할 수 있습니다. 이처럼 상반된 가정을 가진 검정들을 동시에 사용하는 것은 시계열의 정상성 여부를 판단하는 데 내재된 통계적 모호성을 인정하고 모델의 견고성을 확보하기 위함이며, 이는 ARIMA 모델의 'I' 항(차분 횟수 )을 결정하는 데 필수적인 과정입니다.
정상성 진단을 위한 주요 기준은 다음 표에 요약되어 있습니다.
표 I: 시계열 정상성 확인 및 진단 방법
| 정상성 기준 | 그래프 분석 (시간 플롯) | ACF 플롯 | ADF 검정 (: 단위근 존재) | KPSS 검정 (: 정상성) |
| 정상 시계열 | 평균이 일정, 분산 일정 | 빠르게 0으로 감소 (Cut-off) | 기각 (p < ) | 기각 실패 (p > ) |
| 비정상 시계열 | 추세/계절성 존재, 분산 증가 | 느리게 감소 또는 양수 값 유지 | 기각 실패 (p > ) | 기각 (p < ) |
II. 단변량 모델링: AR, MA, ARMA, 그리고 ARIMA의 완성
ARIMA 모델은 단일 시계열 데이터의 내부적인 시간 구조(자기상관성)를 포착하여 미래를 예측하는 고전적인 선형 모델입니다.
2.1 자기회귀 모델 (AR: Autoregressive Model)
자기회귀(AR) 모델은 현재 시점의 관측치()가 과거 시점까지의 자신의 관측치()에 선형적으로 의존한다고 가정합니다. 즉, 현재 값은 과거 값들이 일정 비율로 회귀된 결과로 설명됩니다.
AR(p) 모델의 수식적 정의:
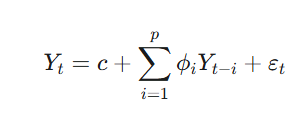
여기서 는 상수항, 는 자기회귀 계수, 는 백색잡음 오차항입니다. AR 모델이 정상 과정을 나타내기 위해서는 특성 방정식의 모든 근(Root)이 단위근(Unit Circle) 밖에 위치해야 한다는 정상성 조건(Stability Condition)을 만족해야 합니다. 이 조건은 모델의 예측값이 과거 의존성에 의해 무한정 발산하는 것을 방지합니다.
AR(p) 모델의 식별은 PACF (부분 자기상관 함수) 플롯을 통해 이루어지는데, PACF는 시차 이후에 **절단(Cut-off)**되는 형태를 보입니다. 반면, ACF 플롯은 과거의 영향력이 무한한 시차까지 미치기 때문에 서서히 감소하는(Decay) 형태를 보입니다.
2.2 이동평균 모델 (MA: Moving Average Model)
이동평균(MA) 모델은 현재 시점의 관측치가 과거 시점까지의 예측 오차항()의 선형 조합으로 표현된다고 가정합니다. 이는 단기적인 충격(Shocks)이 현재 값에 미치는 잔존 효과를 모델링하는 데 유용합니다.
MA(q) 모델의 수식적 정의:

여기서 는 평균, 는 이동평균 계수, 는 현재의 오차항입니다. MA 모델은 항상 정상성을 만족하지만, AR() 형태로 변환 가능하기 위한 가역성 조건(Invertibility Condition)이 필요합니다.
MA(q) 모델의 식별은 ACF 플롯을 통해 이루어지는데, ACF는 시차 이후에 **절단(Cut-off)**되는 형태를 보입니다. 오차항의 영향이 유한한 시차까지만 직접적으로 미치기 때문입니다. 반면, PACF 플롯은 서서히 감소하는 형태를 보입니다.
ARIMA 모델에서 ACF와 PACF의 상반된 행동(Cut-off 대 Decay)은 시계열의 '기억' 메커니즘이 과거 관측치에 직접 기인하는지(AR), 아니면 단기적인 혁신(shock)에 기인하는지(MA)를 해독하는 통계적 지문(fingerprint) 역할을 합니다.
2.3 ARMA 모델과 ARIMA 모델의 통합
ARMA(p, q) 모델은 정상 시계열을 가정하며, AR 성분과 MA 성분을 결합하여 시계열의 자기상관 구조를 포괄적으로 모델링합니다. ARMA(1, 0)은 AR(1)과 같고, ARMA(0, 1)은 MA(1)과 같습니다. ARMA(1, 1)은 가장 흔하게 관찰되는 정상 시계열 모델 형태 중 하나입니다.
ARIMA(p, d, q) 모델은 비정상 시계열을 다루기 위한 최종적인 확장 형태입니다.
- : 자기회귀 항 (p 시차)
- : 통합(Integrated) 항, 즉 차분 횟수 (d차)
- : 이동평균 항 (q 시차)
ARIMA 모델은 비정상 시계열 에 차분(번)을 적용하여 정상 시계열()을 만든 후, 이 정상 시계열에 ARMA(p, q) 모델을 적용하는 개념입니다. 여기서 항이 가지는 의미는 단순한 추세 제거 이상의 중요성을 가집니다. 이라는 것은, 원본 시계열이 단위근을 포함하여 무한한 분산을 가진 확률보행 과정의 성격을 내포하고 있다는 의미이며, 따라서 장기 예측 오차의 분산은 예측 기간이 길어질수록 무한대로 증가하는 경향을 보입니다. 'I' 항의 결정은 이러한 비정상 과정의 불확실성을 모델링하는 핵심 요소입니다.
2.4 모델 식별 및 진단 절차
ARIMA 모델 구축 시, ACF와 PACF 플롯을 분석하여 차분 횟수 를 정한 후, AR 차수 와 MA 차수 를 결정합니다. ACF와 PACF가 모두 서서히 감소하는 형태를 보인다면 ARMA(p, q) 모델이 적합하며, 이 경우 AIC(Akaike Information Criterion), BIC(Bayesian Information Criterion) 등의 정보 기준을 사용하여 최적의 와 조합을 선택합니다.
모델 차수를 선택할 때는 파시모니(Parsimony, 간결성)의 원칙을 따라야 합니다. 차수가 올라간다고 해서 모델의 성과나 예측 정도가 반드시 올라가지는 않으며, 오히려 과적합 위험을 높일 수 있습니다. 따라서 가능한 한 적은 파라미터로 데이터를 잘 설명하는 간결한 모델을 선호합니다.
모델 적합 후에는 잔차 가 백색잡음 가정을 만족하는지 진단해야 합니다. 융-박스(Ljung-Box) Q* 통계는 잔차에 여전히 자기상관이 남아있는지 확인하는 통계적 검정입니다. 이 검정에서 p-값이 크다면(예: 0.05보다 크다면 귀무가설 기각 실패), 잔차가 백색잡음임을 지지하며, 모델이 적절하게 시계열 구조를 포착했음을 의미합니다.
표 II: ARIMA 모델 식별을 위한 ACF 및 PACF 행동
| 모델 형태 | ACF (자기상관 함수) | PACF (부분 자기상관 함수) |
| AR(p) | 서서히 지수적으로 감소 (Decay) | p 시차 이후 절단 (Cut-off) |
| MA(q) | q 시차 이후 절단 (Cut-off) | 서서히 지수적으로 감소 (Decay) |
| ARMA(p, q) | 둘 다 서서히 감소 (Decay) | 둘 다 서서히 감소 (Decay) |
III. 다변량 모델링: 벡터 자기회귀 (VAR: Vector Autoregression)
ARIMA 모델이 단일 변수의 과거 패턴에 기반하여 예측하는 데 초점을 맞춘다면, VAR(Vector Autoregression) 모델은 여러 시계열 변수 간의 동태적인 상호작용과 인과 관계를 동시에 분석하고 예측하는 다변량 확장 모델입니다.
3.1 VAR 모델의 개념 및 가정
현실 세계의 경제 및 금융 데이터는 이자율, 물가, 통화량 등 여러 변수들이 상호 의존적(Interdependent)입니다. 단일 변수 예측으로는 이러한 변수 간의 피드백 루프(Feedback Loop)를 포착할 수 없기 때문에 VAR 모델이 필요합니다.
VAR 모델은 개의 시계열 변수들의 벡터 가 과거 자신의 값과 다른 모든 변수의 과거 값에 선형적으로 의존한다고 가정합니다. VAR 모델링을 적용하기 위해서는 모든 변수가 정상성(Stationarity)을 띠어야 한다는 기본 가정이 있습니다. VAR 모델에서는 모든 변수가 **내생적(Endogenous)**이라고 간주되며, 이는 모든 변수 간의 인과 관계가 상호적으로 존재함을 내포합니다.
3.2 VAR 모델의 수식적 정의 및 구조
시차 를 가지는 VAR(p) 모델의 벡터 수식 표현은 다음과 같습니다:
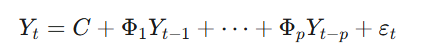
여기서 는 개의 변수를 포함하는 벡터, 는 절편 벡터, 는 시차 에 해당하는 크기의 계수 행렬, 는 오차항 벡터입니다.
VAR 과정이 안정적이고 정상성을 가지려면, 특성 다항식의 모든 근(Eigenvalues)이 단위근 밖에 위치해야 한다는 안정성(Stability) 조건을 만족해야 합니다. 이 조건은 다변량 시스템의 장기적인 예측 가능성을 보장합니다.
3.3 VAR 모델의 식별 및 추정
VAR 모델 구축의 핵심은 최적 시차(Lag Length, )를 결정하는 것입니다. 시차가 너무 짧으면 변수 간의 중요한 자기상관 구조를 포착하지 못하고, 시차가 너무 길면 모델의 자유도가 감소하고 추정의 비효율성이 증가합니다. 최적 시차 를 선택하기 위해 AIC, BIC, HQIC 등의 정보 기준이 사용되며, 이 중 BIC가 일반적으로 가장 보수적인(짧은) 시차를 선택하는 경향이 있습니다.
VAR 모델은 각 방정식을 독립적인 최소자승법(OLS)을 사용하여 효율적으로 추정할 수 있습니다.
VAR과 비정상성의 문제: 만약 비정상적인 시계열을 사용하여 VAR 모델을 구축하고 차분을 사용하지 않는다면, 허위 회귀(Spurious Regression) 문제가 발생하여 통계적 유의성이 과장될 수 있으며, 이는 모델의 해석력을 심각하게 훼손합니다. 따라서 VAR을 적용하기 전에 모든 변수의 정상성을 단위근 검정으로 엄격하게 확인해야 합니다.
3.4 VAR 모델의 심층 분석 도구
VAR 모델은 예측 자체보다 시스템 내부의 동태적 관계를 분석하는 데 강력한 장점을 가집니다.
- 충격반응함수 (Impulse Response Function, IRF): IRF는 한 변수의 오차항에 가해진 1 표준편차의 충격(shock)이 시간이 지남에 따라 다른 변수들(그리고 자신)에 미치는 동태적인 영향력을 분석하는 데 사용됩니다. 이는 특정 경제적 충격이 시스템 내에서 어떻게 전파되고 소멸하는지를 시각적으로 보여줍니다.
- 분산 분해 (Variance Decomposition, VD): VD는 특정 변수의 예측 오차 분산에 대해 시스템 내 각 변수의 혁신(Innovation)이 기여하는 상대적인 비율을 분석합니다. 이를 통해 변수 간의 상대적인 중요도와 인과 관계의 방향성을 정량화할 수 있습니다.
3.5 구조적 VAR (Structural VAR, SVAR) 모델
표준 VAR 모델의 오차항은 동시적으로 발생하는(Contemporaneous) 충격 간의 상관관계를 포함하고 있을 수 있습니다. 따라서 VAR의 혁신(오차항)을 곧바로 경제학적 의미를 가진 '구조적 충격'으로 해석하기 어렵습니다.
SVAR 모델은 이러한 문제점을 해결하기 위해 도입되었습니다. SVAR은 오차항 벡터에 추가적인 제약 조건(Identification)을 가하여 동시적 충격 간의 상관관계를 제거하고, 경제학적으로 의미 있는 구조적 충격(예: 통화 정책 충격, 공급 충격)을 식별합니다. 식별 방법으로는 Cholesky 분해(변수 간의 일방적인 순서를 가정)나 경제학적 이론에 기반한 제약 조건 설정이 사용됩니다. VAR 모델이 단순히 예측에 중점을 둔다면, SVAR은 정책 분석 및 경제학적 인과관계 해석에 주력합니다.
IV. ARIMA와 VAR의 비교 및 고급 주제
4.1 ARIMA vs. VAR: 단변량 대 다변량의 근본적 차이
ARIMA와 VAR 모델은 접근 방식과 목적에서 근본적인 차이를 보입니다. ARIMA는 단일 변수의 예측 정확도를 최대화하기 위해 내부 구조(자기상관성)를 모델링하는 데 최적화되어 있습니다. 반면, VAR은 여러 변수 간의 동태적 상호작용과 피드백 효과를 분석하여 시스템 전반의 움직임을 이해하는 데 중점을 둡니다.
VAR 모델은 데이터 요구사항이 높고(변수 와 시차 에 따라 계수 행렬 의 크기가 급증), 시차 선택 및 안정성 조건 검토가 더 복잡합니다. 하지만 IRF와 VD를 통해 얻을 수 있는 해석의 폭이 훨씬 풍부합니다. 특히, 분석의 목표가 단순한 예측 정확도를 넘어 경제 시스템 내의 구조적 해석이나 정책 시뮬레이션으로 이동할 때, VAR 모델이 필수적입니다.
표 III: ARIMA와 VAR 모델의 주요 특징 비교
| 특징 | ARIMA (Autoregressive Integrated Moving Average) | VAR (Vector Autoregression) |
| 분석 대상 | 단변량 (Univariate) 시계열 | 다변량 (Multivariate) 시계열 |
| 목표 | 단일 변수의 과거 패턴 기반 미래 예측 | 변수 간의 동태적 상호작용 및 공동 예측 |
| 정상성 처리 | 차분(I)을 통해 단일 변수를 정상화 | 모든 변수가 정상이어야 함 (비정상 시 VECM 고려) |
| 분석 도구 | ACF, PACF, Ljung-Box Q | IRF, 분산 분해 (VD) |
| 핵심 가정 | 오차항의 백색잡음 가정 | 모든 변수가 내생적이라는 가정 |
4.2 확장된 시계열 모델: VECM (Vector Error Correction Model)
VAR 모델을 비정상 시계열에 적용할 때 중요한 고급 개념은 **공적분(Cointegration)**입니다. 공적분은 두 개 이상의 비정상 시계열이 개별적으로 추세를 가지더라도, 이들이 장기적으로 안정적인 선형 관계(공적분 관계)를 유지하는 경우를 의미합니다. 이는 변수들이 장기적인 균형 관계에서 이탈하면 다시 균형으로 회귀하려는 경향이 있음을 나타내는 중요한 경제적 정보입니다.
공적분 관계가 존재할 때 단순히 차분된 시계열을 VAR에 적용하면, 변수들이 장기적으로 함께 움직여야 한다는 정보(균형 관계)가 소실됩니다.
벡터 오차수정 모델 (VECM)은 이 문제를 해결하기 위해 사용됩니다. VECM의 역할은 비정상성 시계열을 처리하는 방식을 단순한 '제거' (차분)에서 장기 균형 관계를 포함하는 '모델링'으로 진화시키는 것입니다.
- VECM 적용 조건: 모든 변수가 비정상적이지만, 공적분 관계가 존재할 경우 VECM을 사용해야 합니다.
- VECM의 구조: VECM은 기본적으로 차분된 VAR 형태이지만, 여기에 장기적인 균형 관계로부터의 이탈 정도를 나타내는 **오차수정항(Error Correction Term, ECT)**이 추가됩니다. VECM은 단기적인 동태(차분 항)와 장기적인 균형 복원 메커니즘(ECT)을 모두 모델링할 수 있는 강력한 도구입니다.
4.3 실용적 적용 및 예측 정확도 평가
모델 적합 후에는 예측의 정확성을 객관적으로 평가해야 합니다. 주요 평가 지표로는 평균 제곱근 오차(RMSE), 평균 절대 오차(MAE), 평균 절대 백분율 오차(MAPE) 등이 활용됩니다. 시계열 데이터의 특성상 과거와 미래가 독립적이지 않으므로, 일반적인 교차 검증 대신 롤링 윈도우(Rolling Window) 기법을 사용하여 모델의 시점별 안정성과 일반화 능력을 평가하는 것이 일반적입니다.
ARIMA와 VAR은 모두 선형 모델이며, 주식 시장의 갑작스러운 구조적 변화(Structural Breaks)나 변동성 클러스터링(Volatility Clustering)과 같은 비선형적인 관계를 포착하는 데 한계가 있을 수 있습니다. 이러한 한계점을 극복하기 위해 ARCH/GARCH 계열 모델이나 최근에는 딥러닝 기반의 시계열 모델이 연구 및 활용되고 있습니다.
참고 자료
- 정상성과 차분 (stationarity & differencing) - 데이터과학 삼학년, 9월 30, 2025에 액세스, https://dodonam.tistory.com/233
- 8.1 정상성과 차분 | Forecasting: Principles and Practice - OTexts, 9월 30, 2025에 액세스, https://otexts.com/fppkr/stationarity.html
- 시계열 분석 시리즈 (1): 정상성 (Stationarity) 뽀개기 | Be Geeky, 9월 30, 2025에 액세스, https://assaeunji.github.io/statistics/2021-08-08-stationarity/
- [시계열] 시계열 모델 기초(1) 안정시계열 -AR , MA , ARMA (세상에서 제일 쉬운 설명), 9월 30, 2025에 액세스, https://datasciencefromsebi.tistory.com/67
- 시계열 분석, ARIMA model (Autoregressive Integrated Moving average Model) - 동구리의 All of the Data - 티스토리, 9월 30, 2025에 액세스, https://dong-guri.tistory.com/9
'독학,외부강의 > 통계학' 카테고리의 다른 글
| [ 자격 ] 사회조사분석사 2시간 요약 (0) | 2026.01.29 |
|---|---|
| [ 통계학 ] 앤더슨 통계학 2장 기술통계량 (0) | 2019.01.20 |
| [통계학] 앤더슨 통계학 - 1장 (0) | 2019.01.20 |